在 Day 18、Day 19、Day 20的文章中,我們設計了從 OTel Collector 到 S3 Table 的 data pipeline,不過,在成功儲存資料後,我們便要去思考要如何快速地從 Data Lakehouse 中有效率地去做查詢。
尤其對於可觀測性資料來說,一個系統每天可能會產生數百萬筆的 Metrics,當故障發生時,你可能需要在短時間內找出過去幾小時內的系統資源使用量。假設查詢需要掃描整個資料表,可能要等待數分鐘,這對於故障排查來說是無法接受的。 今天我們將探討如何透過分區策略和 Iceberg 的優化機制,讓查詢效能提升數倍甚至數十倍。
即使是 RDBMS,在查詢資料時,我們也會盡量避免全表搜尋導致的效能低落。而在 Data Lakehouse 中也是如此,其查詢效能的核心原則是「只讀取必要的資料」。
以 Athena 為例,假設我們要查詢過去一小時的 HTTP 請求量:
SELECT service_name, COUNT(*) as request_count
FROM metrics_db.http_metrics
WHERE timestamp >= TIMESTAMP '2024-01-15 14:00:00'
AND timestamp < TIMESTAMP '2024-01-15 15:00:00'
GROUP BY service_name
以上的 SQL 雖然有限制其撈取範圍,但它還是撈取了所有欄位的資料,在這樣的狀況下,SQL 會去掃描整個資料表的所有檔案,讀取所有 Parquet 檔案的所有欄位,最後才過濾出符合時間範圍的資料。
這樣的狀況下,可能我們掃描了 100 GB 的資料,最後可以被拿來做參考的資料只有 500 MB。
查詢效能的優化主要可以透過三個面向達成:
資料分區(Partitioning)透過將大型的資料分隔成更小、更易於管理的子集,是提升查詢效能最直接的方式。透過分區技術,在查詢的時候,查詢引擎就可以直接跳過不相關的分區。
可觀測性資料通常都是時間序列資料,因此以時間作為分區是最常見的方式。
CREATE TABLE metrics_db.http_metrics (
timestamp TIMESTAMP,
service_name STRING,
metric_name STRING,
value DOUBLE,
method STRING,
status STRING
)
USING ICEBERG
PARTITIONED BY (day(timestamp))
LOCATION 's3://my-table-bucket/metrics_db/http_metrics/'
這個定義使用了 Iceberg 的 partition transform:days(timestamp),它會自動將 timestamp 轉換為日期分區。 實際的儲存結構會像這樣:
s3://my-table-bucket/metrics_db/http_metrics/
├── data/
│ ├── timestamp_day=2024-01-15/
│ │ ├── file1.parquet
│ │ ├── file2.parquet
│ ├── timestamp_day=2024-01-16/
│ │ ├── file1.parquet
當我們查詢特定日期的資料時,Athena 只會讀取對應分區的檔案。
對於資料量更大的場景,僅使用時間分區,撈出來的資料量也可能過於龐大,這時候就可以考慮多層分區:
PARTITIONED BY (days(timestamp), service_name) -- 先按日期分區,再按服務名稱分區
雖然分區可以提升查詢效率,不過過多的分區可能造成大量小檔案的產生,進一步產生 metadata 的儲存成本。對於高基數的欄位如 user_id 等,也盡量避免設為分區鍵(partition key),同樣也是為了避免過多的分區產生。
不過,若資料檔案內的分布過於隨機,即使已經定義了分區,也可能因為查詢時必須掃描大量無關檔案而拖慢效能。此時,可以透過 排序(Sort Compaction) 或 Z-Order Clustering 來改善檔案的物理布局。
在 Sort Compaction 策略下,Iceberg 會依照指定欄位(例如 region、service_name)重新排列資料檔案,讓相似值被聚集在一起。這樣當查詢對該欄位進行篩選時,查詢引擎(如 Athena 或 Spark)能有效跳過不相關的檔案,減少 I/O 掃描。
而 Z-Order Clustering 則進一步針對多個維度進行優化。它會將多個欄位(例如 region, metric_name, status)的值經過二進位交錯編碼後,生成一個排序鍵,讓多欄位的關聯性在物理層面上更緊密。這對於同時根據多個欄位進行篩選的查詢特別有效,能顯著減少需要掃描的檔案數量。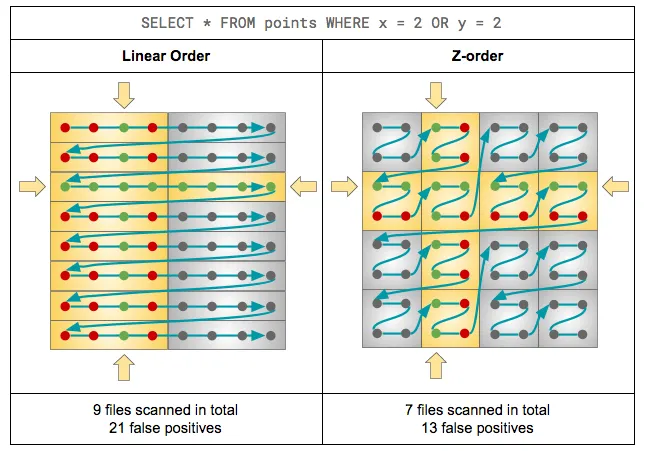
除了分區,Iceberg 還透過豐富的 metadata 來加速查詢。
Iceberg 會為每個資料檔案記錄統計資訊:
{
"data_file": "file1.parquet",
"record_count": 50000,
"file_size_in_bytes": 10485760,
"column_stats": {
"timestamp": {
"min": "2024-01-15T10:00:00Z",
"max": "2024-01-15T10:59:59Z"
},
"status": {
"distinct_count": 5,
"null_count": 0
}
}
}
當執行查詢時,Athena 可以利用這些統計資訊:
SELECT * FROM http_metrics
WHERE timestamp >= TIMESTAMP '2024-01-15 11:00:00'
Athena 會檢查每個檔案的 timestamp.min 和 timestamp.max,如果時間範圍不重疊,直接跳過該檔案,不需要實際讀取。
Iceberg 的 column statistics 本質上是一種 min-max index。對於每個資料檔案,Iceberg 會記錄每個欄位的最小值和最大值。 這讓範圍查詢變得非常高效:
-- 只會讀取 value > 1000 的檔案
SELECT * FROM http_metrics
WHERE value > 1000
這樣,Athena 會直接跳過 value.max < 1000 的檔案,而不會重新掃過 value <= 1000的數值。
以上講的都是資料層的優化,不過在 Athena query 本身也有優化的空間,以下是一些在撰寫 query 時可以注意的地方。
如前面所說,可觀測性資料可能會擁有非常多的欄位來記錄資料,卻不是每次故障事件都需要這麼多欄位。讀取特定欄位,對於像 Parquet 這種欄式儲存的資料格式來說能大幅增加查詢效能。
如果我們在分區欄位中再進行函數運算,就無法利用分區過濾資料了。
SELECT * FROM http_metrics
WHERE DATE(timestamp) = DATE '2024-01-15'
因此會建議直接在 WHERE 子句中包含分區欄位,來達到真正的分區效果。
-- 探索性查詢時使用 LIMIT
SELECT * FROM http_metrics
WHERE timestamp > TIMESTAMP '2024-01-15'
LIMIT 100
Athena 的執行引擎會盡早停止掃描,節省查詢時間和成本。
Data Lakehouse 雖能夠海納百川,從不同的角度取得系統的可觀測性資料,但要如何有效率地去查詢這些資料更是系統設計的關鍵。透過今天的介紹,我們可以瞭解到:
這些優化可以將查詢效能提升數十倍甚至數百倍,讓 Data Lakehouse 真正成為可用於即時故障排查的可觀測性平台。
Apache Hive - LanguageManual DML
Apache Iceberg - Spark Queries
AWS Documentation - Optimize Athena performance
HOGAN.B LAB - Data Partitioning 資料分區是什麼? – 系統設計 10
Kumar Gautam - Best Practices for Implementing Apache Iceberg: Lessons from the Field
OneHouse - Apache Hudi™ Z-Order and Hilbert Space Filling Curves

